
LLM for Text2SQL: Paper Notes and Thoughts Beyond Paper (2024)
At work, I noticed a need to help the business team automate data ingestion from sources like hardware, slides, and Excel into cloud databases like RedShift or BigQuery. This would streamline downstream tasks such as dashboards, alert emails, and metric calculations. However, the team isn't familiar with SQL, so making database queries accessible to non-technical users seems crucial. Since this hasn't been formally requested, I decided to explore potential solutions on my own. My goal is to understand how to deliver accurate results without over-promising on current capabilities.
Text-to-SQL (text2SQL) is a natural language processing (NLP) task that involves converting a natural language query into a structured SQL query. This allows users to interact with a database by simply typing or speaking their questions in plain language, and the system then translates that input into an SQL query that can be executed on the database. I believe that achieving accuracy in this system requires a blend of NLP techniques and an understanding of database schema.
In this post, I'll focus on using large language models (LLMs) to tackle this challenge, mainly covering research papers released from Apr 2023 onwards. Although this isn't my main expertise, I aim to share what I learn through this exploration, not as a technical guide but as an honest account of my findings.
I'll also be sharing two more posts: one focused on exploring open-source and publicly accessible tools, and another on a lightweight trial using a self-organized dataset, applying all the techniques I've learned along the way.
As usual, we begin with a survey to get a comprehensive view of this area. I came across one titled "A Survey on Employing Large Language Models for Text-to-SQL Tasks" (August 2024). The survey highlights the evolution from template-based and rule-based methods to deep learning models, then pre-trained language models (PLMs), and now to the current stage dominated by large language models (LLMs).
Roughly from Apr 2023, newly released papers are starting to use LLM for text2SQL (https://paperswithcode.com/sota/text-to-sql-on-spider)
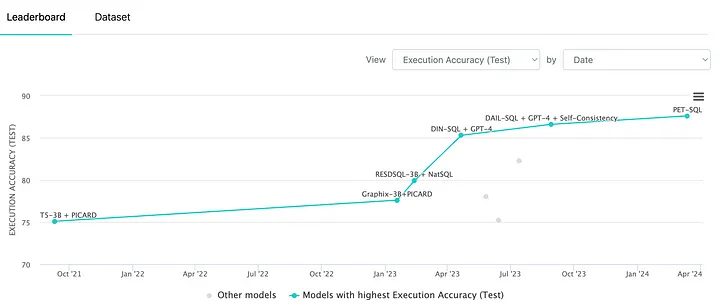
Timeline of Text-to-SQL papers and their performance on the Spider benchmark
Based on my understanding, the typical text2SQL workflow might look like this: When a user submits a request, we can construct a prompt template using the query (which can be further refined by the LLM). We then fetch the relevant table schema and column definitions from the database, gather information from a knowledge database (like similar requests), and send the complete prompt to the LLM. The LLM generates the SQL scripts, which are then executed against the database, with the results returned to the user.
There are a few key areas for optimization:
- Prompt Engineering: This includes incorporating diverse supplementary knowledge, selecting relevant examples, and applying logical reasoning.
- Fine-tuning: Using natural language queries, table schema, and golden SQL queries to fine-tune the model. LLMs can also assist in data preparation and model evaluation.
Example to explain popular text2SQL workflow (disclaimer: I draw this based on my understanding, which might not be same as the survey)
In this survey, it mentions there are 2 important benchmark dataset BIRD and Dr.Spider in this area. We can easily find their leaderboard from paperwithcode(https://paperswithcode.com/task/text-to-sql/latest), and these metrics might be good reference when we want to pick one model for POC first.
Prompt Engineering
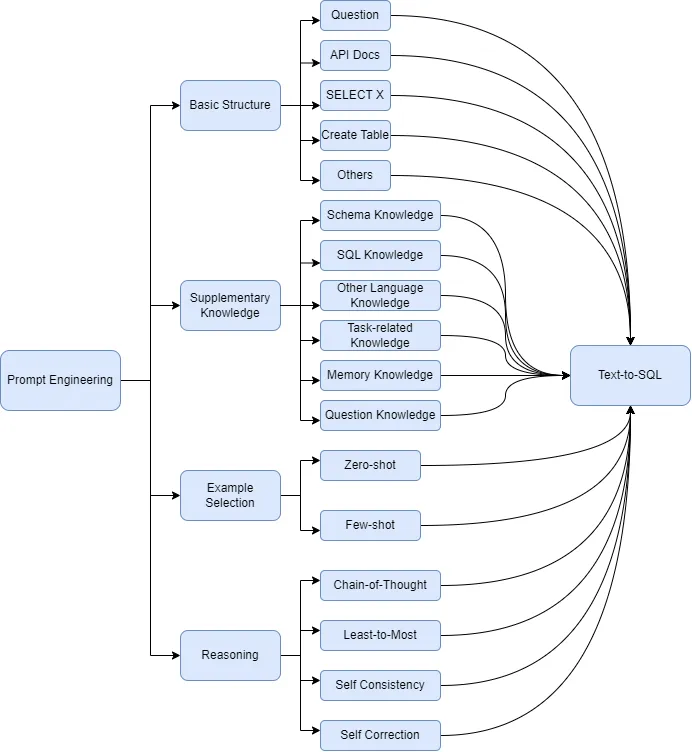
Taxonomy of Prompt Engineering in Text-to-SQL (ref: https://arxiv.org/html/2407.15186v2)
Basic Structure
The essential elements in Text2SQL tasks include two types: the natural language problem itself and the organizational form (schema) of the database (ref). Some approaches to Text2SQL prompts focus solely on the natural language query, while others incorporate database schema details, such as table structures and data types, to improve SQL generation. Different prompt strategies, including API documentation, SELECT statements, and CREATE TABLE commands, are used to guide LLMs in generating accurate SQL queries by aligning them with the underlying database format.
Supplementary Knowledge
To enhance the performance of LLMs in Text2SQL tasks, various supplementary knowledge prompts are used, including schema knowledge to focus on relevant database structures, SQL knowledge to improve syntax accuracy, and task-specific knowledge to tailor SQL generation to specific domains. These prompts help guide LLMs to produce more precise and efficient SQL queries by incorporating domain-related rules, refining question understanding, and using memory to manage multi-step operations (saves the results of SQL execution in memory).
Some methods for identifying relevant columns in a query make sense to me. For example:
- Method 1: A two-step schema linking approach, where ChatGPT first identifies the most relevant tables and then the specific columns related to the question.
- Method 2: The LLM uses the natural language query to generate a minimal "hallucinatory" schema, which is then used as an index to retrieve the relevant subsets from the real schema through similarity matching.
Example Selection
To improve Text2SQL performance, examples can be provided to LLMs, with strategies divided into zero-shot, which avoids Text2SQL-specific examples, and few-shot, which includes examples to guide SQL generation. Few-shot methods enhance LLM effectiveness across various steps by offering examples that combine database schema, text queries, and SQL statements, guiding the LLM in accurately generating SQL.
Reasoning
Several strategies enhance LLM performance in Text2SQL tasks. Chain of Thought (CoT) guides LLMs to think step-by-step, improving SQL generation through sequential reasoning. Least-to-Most breaks complex problems into simpler sub-tasks, solving each to build the final SQL. Self-Consistency uses majority voting, where multiple generated SQLs are compared, and the most frequent one is chosen. Self-Correction involves LLMs checking and correcting their SQL output using rules or error feedback from execution logs.
Finetuning
Finetuning might not be applicable for my use case, so we will not put much time here. But still good to know the method to build new datasets for specific use case, and how to evaluate the LLM models.
Prepare New Dataset: Traditional methods for building text2SQL datasets, like manual annotation, are effective but labor-intensive and costly. With advances in NLP, semi-automatic and fully automatic methods have emerged, leveraging LLMs to generate and validate SQL queries more efficiently. These newer methods involve techniques such as crowdsourcing, few-shot learning, and execution-based validation to create high-quality datasets with reduced manual effort.
Finetune: can check LoRA and QLoRA
Model Evaluation can be categorized into three main types:
- Metric Analysis Evaluation, which involves assessing accuracy through metrics like Exact Set Match (EM) and Execution Accuracy (EX);
- Category Analysis Evaluation, which examines model performance across various scenarios, prompt engineering methods, and question difficulties;
- LLM-based Analysis Evaluation, where advanced LLMs are used to compare and analyze model differences, offering insights into the "when, why, how" of model behavior.
DIN-SQL
paper: DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction (Apr 2023)
repo: https://github.com/mohammadrezapourreza/few-shot-nl2sql-with-prompting
In DIN-SQL, researchers broke down tasks into sub-problems, feeding the solutions into LLMs to enhance reasoning performance. By August 2024, few-shot learning and task decomposition had become fairly common, but back in early 2023, these ideas were still quite novel and significantly improved the state of the art, particularly in addressing schema linking challenges.
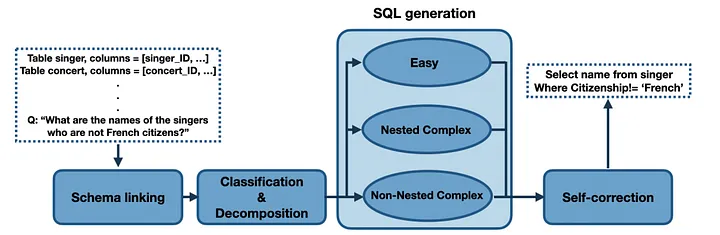
Proposed methodology in DIN-SQL
They start by identifying the necessary tables and columns through schema linking. Then, they apply the Chain-of-Thought method to determine whether the request is a simple query or requires a more complex approach, such as sub-queries. Depending on the difficulty, they use different prompts or steps, and finally, an LLM is employed to self-correct the generated query.
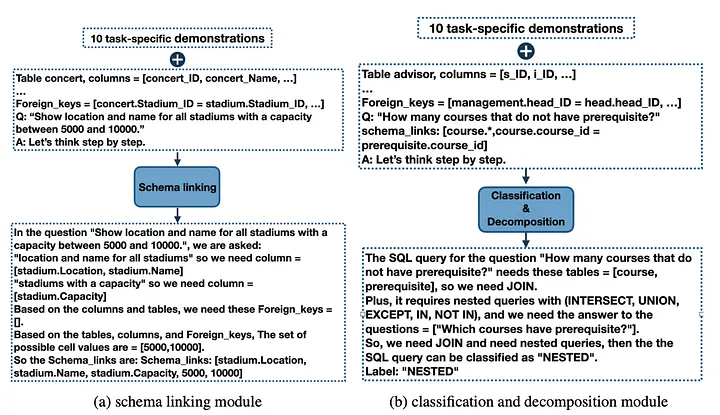
DIN-SQL's step-by-step methodology for query generation and self-correction
I really appreciate their error analysis approach: they randomly sampled queries from different databases, categorized the failures, and used that to guide optimization — it's a very "data science" way of doing things.
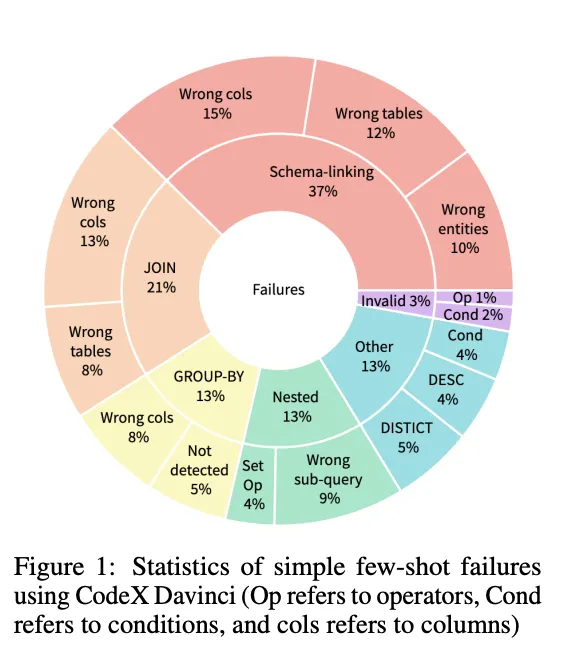
Few Shot Error Analysis (https://arxiv.org/pdf/2304.11015)
C3SQL
paper: C3: Zero-shot Text-to-SQL with ChatGPT (Jul 2023)
repo: https://github.com/bigbigwatermalon/C3SQL
C3SQL focus on zero-shot prompt setting.
- Clear Prompting (CP): focuses on creating effective prompts for Text-to-SQL parsing by improving the clarity of both the layout and context. It distinguishes between a Complicated Layout, which concatenates instructions, questions, and database schema into a messy prompt, and a Clear Layout, which separates these elements with clear symbols, leading to better performance. Additionally, to avoid issues like irrelevant schema items and excessive text length, Clear Context is implemented by using schema linking to include only relevant tables and columns in the prompt. The combination of Clear Layout and Clear Context forms the basis of the proposed Clear Prompt, which improves the accuracy and efficiency of SQL generation.
- Calibration with Hints (CH): addresses two key biases in ChatGPT's SQL generation: a tendency to include unnecessary columns and a preference for using SQL keywords like LEFT JOIN, OR, and IN incorrectly. It uses contextual prompts to guide ChatGPT. Hint 1 focuses on selecting only necessary columns, while Hint 2 aims to prevent the misuse of SQL keywords. These hints help ChatGPT produce SQL queries that better align with the intended output, effectively reducing errors.
- Consistent Output (CO): addresses the instability in ChatGPT's SQL generation due to inherent randomness. There is an execution-based self-consistency method, which involves generating multiple SQL queries, executing them, and then selecting the most consistent result through a voting mechanism.
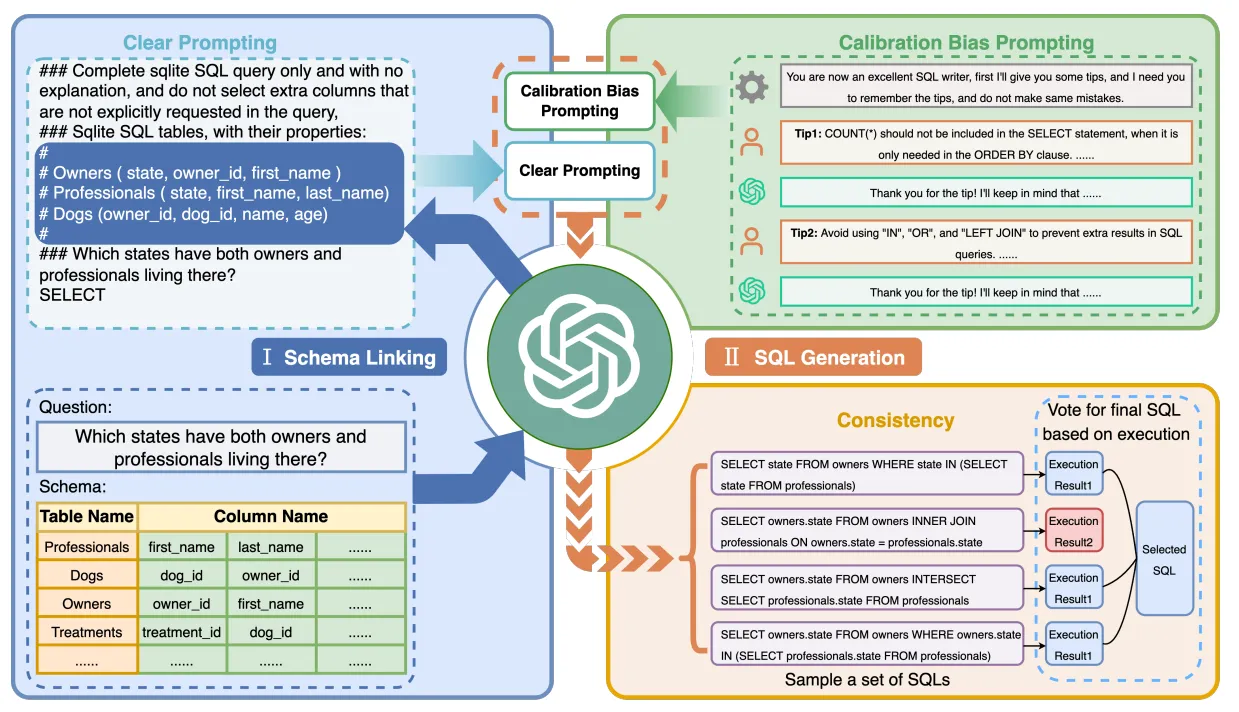
C3SQL's architecture showing Clear Prompting (CP), Calibration with Hints (CH), and Consistent Output (CO) components
DAIL-SQL
Paper: Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation (Aug 2023)
repo: https://github.com/BeachWang/DAIL-SQL?tab=readme-ov-file
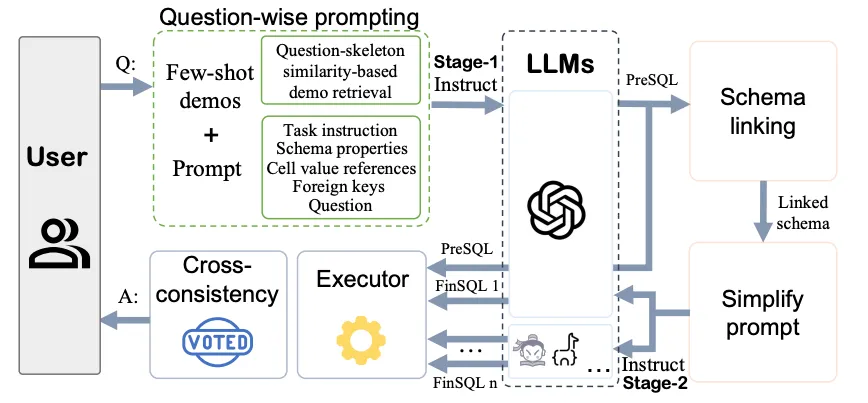
DAIL-SQL conducted a comprehensive comparison of existing prompt engineering methods, including question representation, example selection, and example organization. Based on the results, they picked the best components from these methods to propose a new integrated solution. This is also the approach we aim to take in the future.
From the paper, question representation is one aspect for research.

Question Representation Matters
The discussion of In-context learning focuses on:
- Example Selection: Various strategies, such as random sampling, question similarity, masked question similarity, and query similarity, are employed to choose examples that closely match the target question or SQL query, with some approaches considering both for improved performance.
- Example Organization: Examples are structured in prompts using either full information, which includes question representations and corresponding SQL queries, or SQL-only organization, which maximizes the number of examples by only including SQL queries, highlighting a trade-off between quality and quantity.
With all the experiments, DAIL-SQL proposed the follow method.
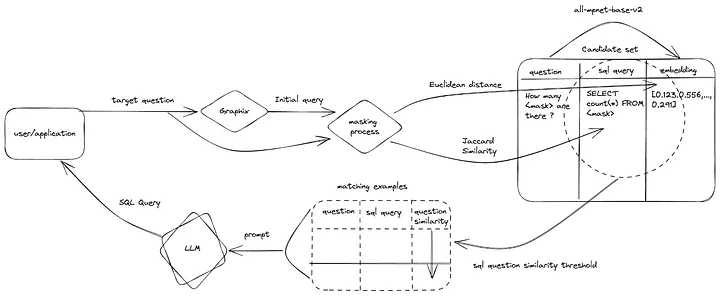
I'm pretty interested in the method proposed. If I have the chance to work on such a project, DAIL-SQL might be my first choice to try.
DBCopilot
paper: DBCopilot: Scaling Natural Language Querying to Massive Databases(Dec 2023)
repo: https://github.com/tshu-w/DBCopilot
DBCopilot addresses a critical challenge in text-to-SQL systems: handling large-scale databases with complex schemas. The paper introduces several key innovations:
- Schema Pruning: A sophisticated approach to reduce the schema size by identifying and removing irrelevant tables and columns, making it possible to work with massive databases within token limits.
- Hierarchical Prompting: A novel method that breaks down complex queries into manageable sub-components, allowing for more accurate SQL generation even with complicated requirements.
- Dynamic Context Window: An adaptive system that adjusts the context window based on the query complexity and schema size, optimizing token usage.
What's particularly interesting is their evaluation on real-world enterprise databases with thousands of tables, showing practical applicability beyond academic benchmarks.
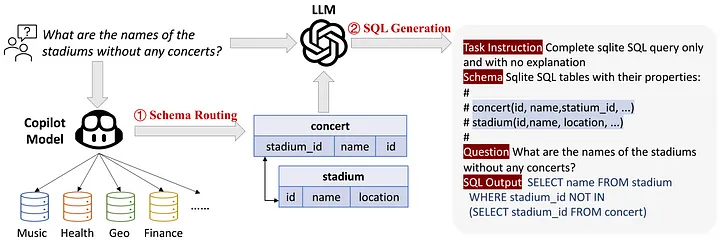
DBCopilot's architecture showing schema pruning and hierarchical prompting components
MAC-SQL
paper: MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL(Dec 2023)
repo: https://github.com/wbbeyourself/MAC-SQL
MAC-SQL takes a unique approach by implementing a multi-agent system where different specialized agents collaborate to generate SQL queries. The framework includes:
- Schema Expert: Focuses on understanding and analyzing database schema, identifying relevant tables and relationships.
- Query Planner: Develops the high-level strategy for constructing the SQL query, breaking down complex requirements into logical steps.
- SQL Writer: Specializes in writing precise SQL syntax based on the plan provided by the Query Planner.
- Reviewer: Validates the generated SQL, checking for logical errors and optimization opportunities.
The agents communicate through a structured protocol, sharing insights and refining the query iteratively. This division of responsibilities leads to more robust and accurate SQL generation, especially for complex queries requiring multiple steps or joins.
MAC-SQL's multi-agent collaborative architecture
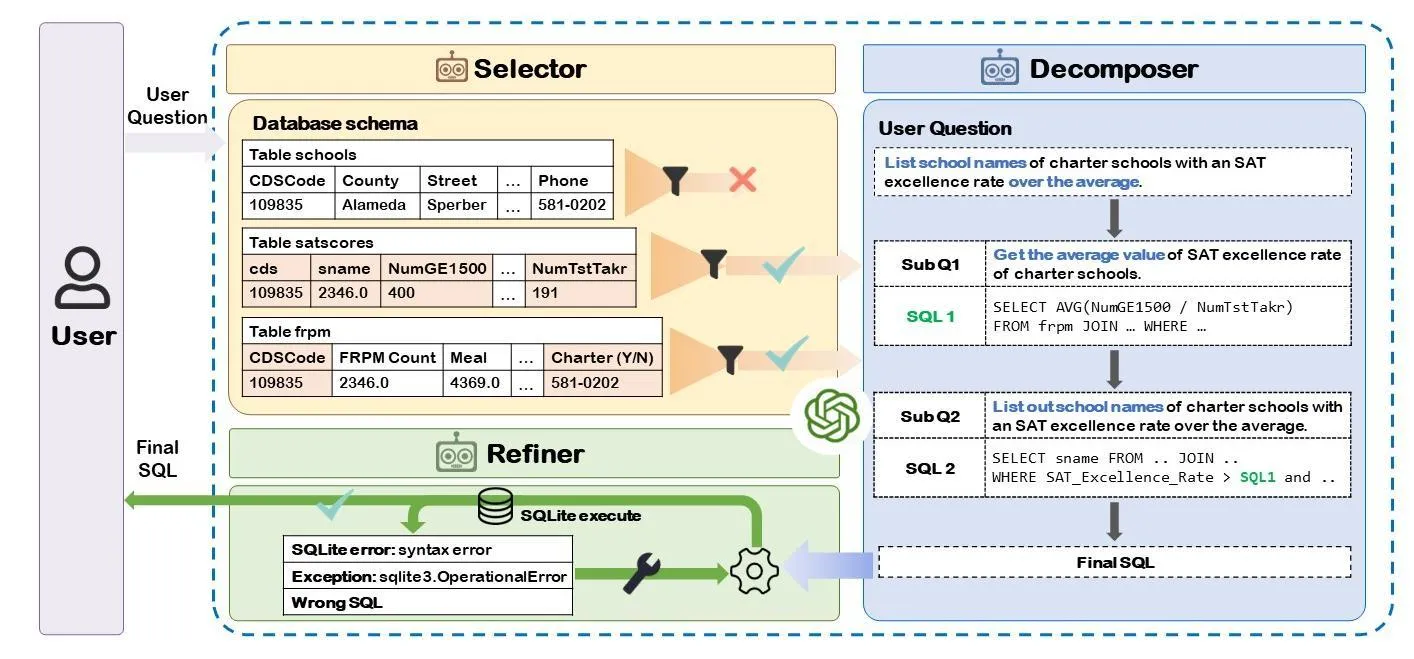
PET-SQL
paper: PET-SQL: A Prompt-Enhanced Two-Round Refinement of Text-to-SQL with Cross-consistency (Mar 2024)
repo: https://github.com/zhshLii/PETSQL
PET-SQL introduces a novel two-round refinement process with cross-consistency checking. Key features include:
- First Round: Generates multiple candidate SQL queries using different prompting strategies.
- Cross-Consistency: Compares the execution results of different candidates to identify potential errors or inconsistencies.
- Second Round: Refines the most promising candidates based on cross-consistency results and additional context.
- Enhanced Prompting: Uses carefully crafted prompts that incorporate schema information, example queries, and execution feedback.
PET-SQL's two-round refinement process with cross-consistency checking
The paper demonstrates significant improvements over previous approaches, particularly in handling complex queries and reducing hallucination errors. The two-round approach provides a balance between exploration (generating diverse candidates) and refinement (improving the most promising ones).
Thinking Beyond Paper
Who is Target User?
This is a bit unclear to me. If the target user is an experienced data professional, they likely already have a good sense of which tables and columns to use and just need a tool to help implement the logic. These users also know how to ask detailed questions, like providing explicit filters, which could simplify the text2SQL problem. In this case, the tool would be a great assistant. However, if we're targeting non-technical users, the challenge is different. If the tool can't guarantee accurate SQL generation, debugging a long query could be difficult, and it might end up complicating things rather than helping.
How to Collect High Quality Queries for RAG / Knowledge Database or Evaluation?
I can foresee it might be one of the most difficult part in developing industrial solution. I reminds me of some painful experience to write column descriptions, feature doc and unit tests for long SQL query.
Schema Linking for Huge Data Warehouse
Despite the many new methods for solving schema linking challenges, real-life applications can still present difficulties. In my previous experience at e-commerce companies, we often had thousands of tables with hundreds of columns each. Including all this information in a prompt would quickly hit token limits, while frequent fine-tuning would be necessary due to the rapid growth of new tables. A practical approach might be to use human expertise or LLMs to narrow down the scope by focusing on specific domains (e.g., payment, order, user, fintech, logistics) and only including relevant tables in the search space when we send request (like a checkbox for domain).
Schema Linking for Ambiguious Column Name
As data users, we often encounter issues like missing column descriptions, different column names for similar data across tables, or identical column names with varying logic. It can be time-consuming to track down table owners to clarify these details, and I'm sure many of us face the same challenge. While I don't have a perfect solution, perhaps it's time to go back to basics — organizing and standardizing table and column names to make everyone's work easier.
Human-in-Loop
Reflecting on our daily work as data analysts or data scientists, we often need to clarify and align with the business team on definitions before creating dashboards or metrics — especially simple terms like NMV and GMV can have different calculations across teams. This interaction step could be integrated into the SQL generation process to ensure accuracy and consistency.
Data Privacy
From what I've seen, since the text2SQL problem is still quite complex for real-life applications, companies often rely on third-party LLM APIs rather than in-house models. This can raise privacy concerns, especially since a company's data warehouse is a critical asset.
SQL Execution Responsibility
Some companies might consider automating the execution of natural language queries, but this approach is risky. It can be difficult to assign responsibility for any issues that arise, and if service account permissions aren't properly managed, there's a risk of unintended operations affecting the data warehouse.
Self-Correction or Quality Judge
For industrial usage, it looks more important to design an LLM-based judge to evaluate the quality of the SQL scripts. If the scripts aren't good enough, a regeneration mechanism can be implemented. This could serve as the last gate in industrial usage.
Frameworks We Would Like To Try In The Next Step
- DB-GPT-Hub: Towards Open Benchmarking Text-to-SQL Empowered by Large Language Models [paper] [code]
- https://github.com/AlibabaResearch/DAMO-ConvAI