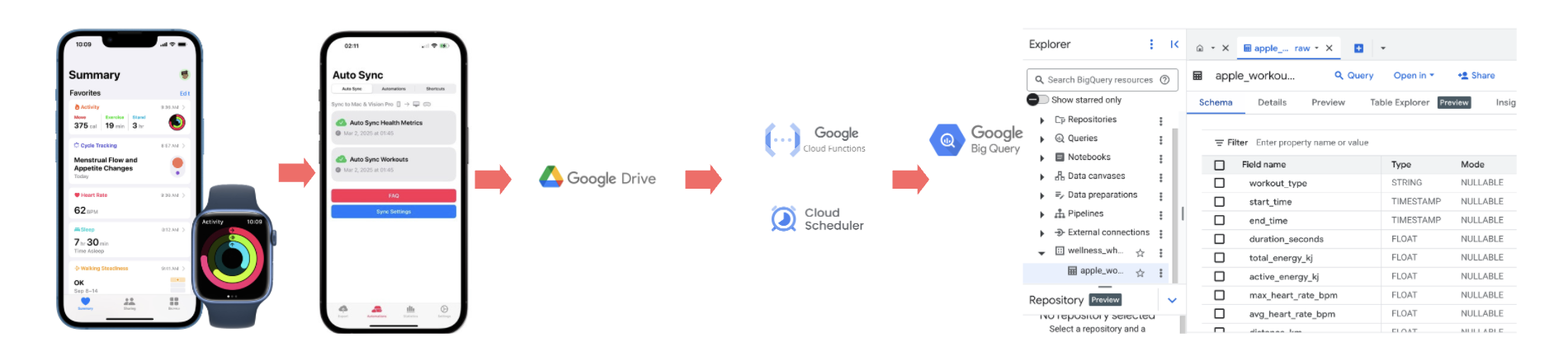
Building a Cloud-Based Data Pipeline: From Apple Health to BigQuery
TL;DR: I built a cloud-based pipeline that ingests my Apple Health data into BigQuery using Health Auto Export, Google Drive, Cloud Functions, and more — all automated, all serverless. Here's how I did it and what I learned.
Disclaimer: The content comes from self-study, rather than anycompany project code.
Auto Collect Apple Health Data
Export from Apple Health app
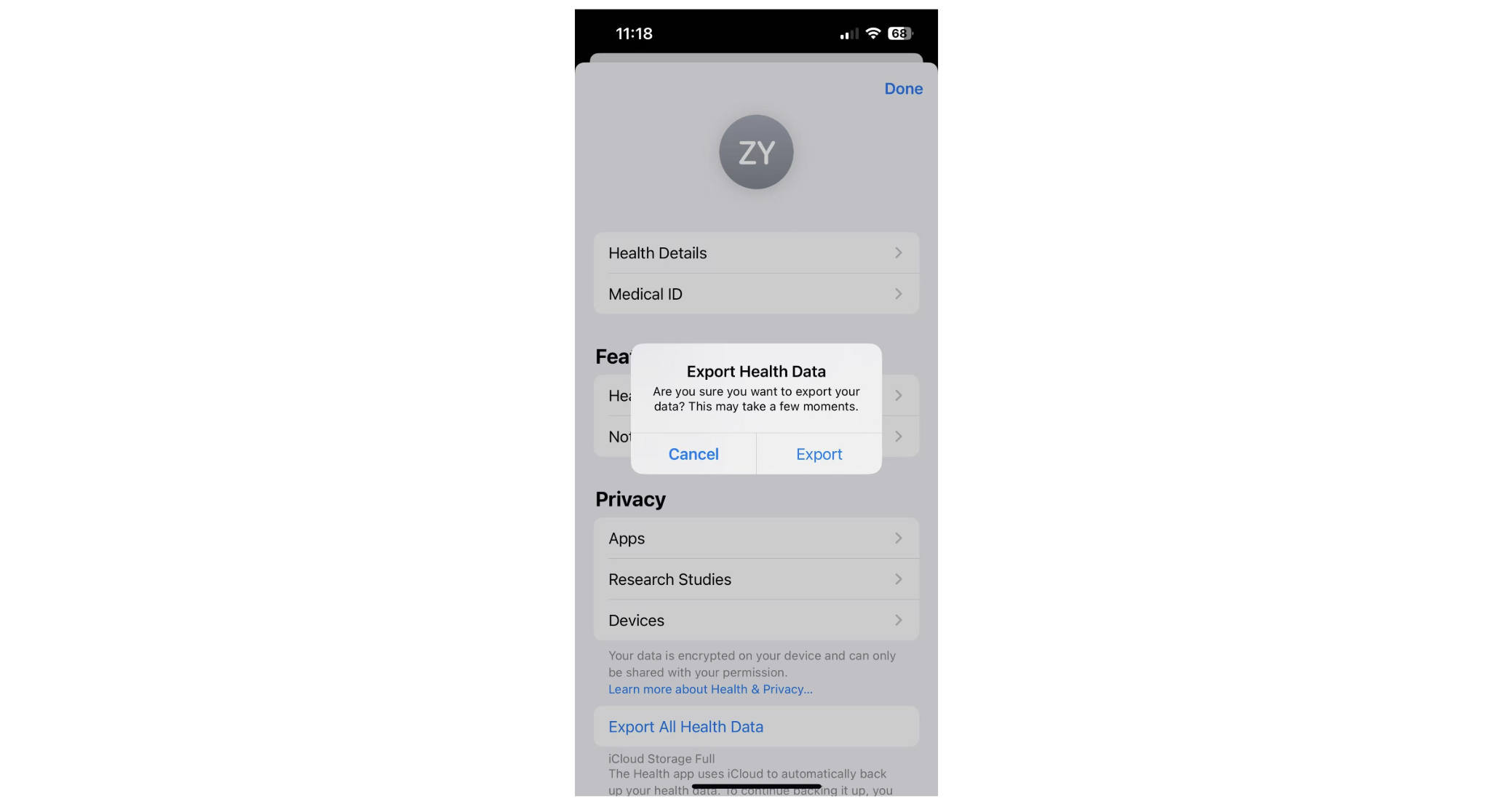
To get started, you'll need to export your Apple Health data from your iPhone. Open the Health app, tap your profile icon in the top right, scroll down, and tap "Export All Health Data." Confirm the export when prompted — your data will be saved as a .zip file containing XML files.
Health Auto Export
(paid service)
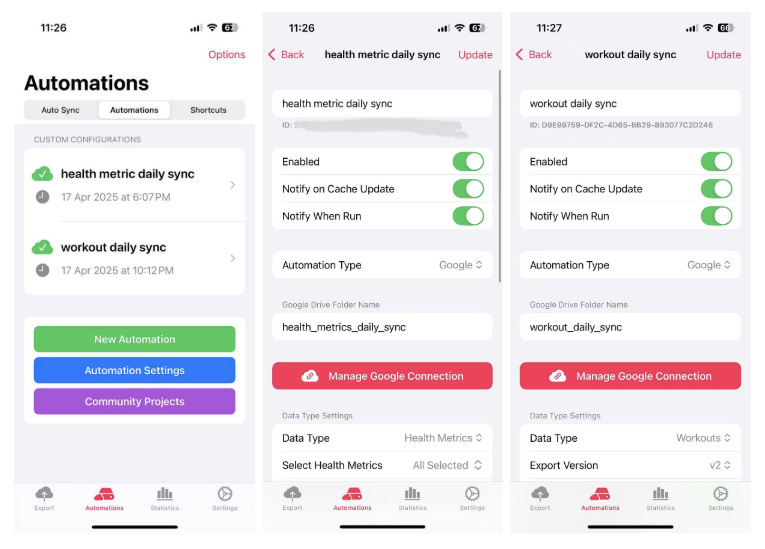
Manually exporting data is fine for one-off analyses, but for a sustainable pipeline, automation is key. That's when I came across a handy iPhone app called Health Auto Export.
This app integrates directly with Apple Health and lets you export your data in JSON or CSV format. With the premium subscription, you can schedule daily automatic exports to a Google Drive folder or even to a REST API endpoint — perfect for building a cloud data pipeline.
To set it up:
- Download Health Auto Export from the App Store.
- Create a new automation (under the Automations tab).
- Choose your data type, e.g., Health Metrics or Workouts.
- Select Google as your automation type and connect your Google Drive account.
- Specify a folder name where the exported files will be saved daily.
- Enable the automation and notifications if desired.
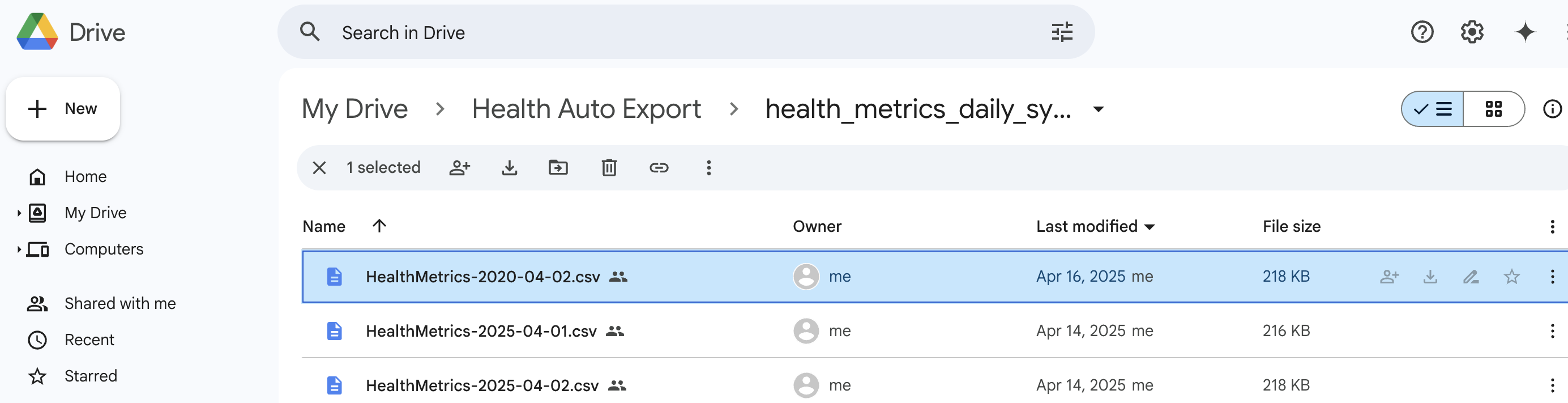
As shown in the screenshots above, I've created two daily syncs: one for general health metrics and another for workouts. This gives me up-to-date data in my Google Drive, which I'll later ingest into BigQuery.
You can also use the manual export function to export all existing data in your phone.
Now we're in business!
Strava API (optional)
It works great as a standalone source or alongside Apple Health data to enrich your dataset with detailed GPS tracks, elevation, segment efforts, and even gear usage — great for deeper analysis later on!
Strava's generous free tier and rich metadata make it a perfect complement to an automated fitness data pipeline.
We will have another post to explore it.
Data Flow
Apple Health & Workouts:
Data is collected via the Apple Health app on iPhone and Apple Watch.
Health Auto Export App:
A third-party iOS app called Health Auto Export is used to automate daily exports of:
- Health Metrics (e.g. heart rate, steps, sleep)
- Workout Sessions (e.g. run, walk, cycling)
These are saved as .csv files directly to Google Drive (via built-in automations).
Google Drive → BigQuery Ingestion:
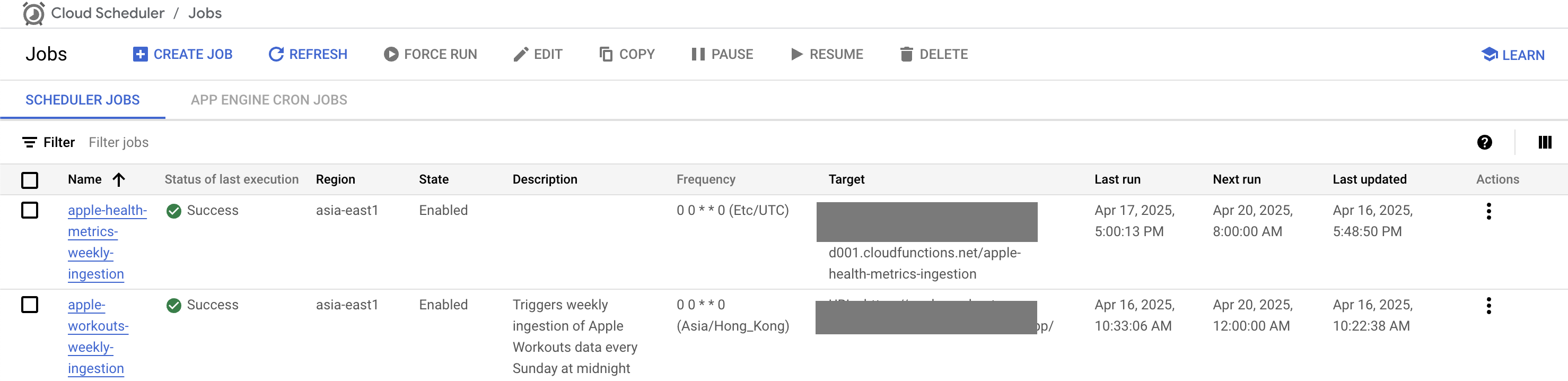
A Cloud Scheduler triggers Cloud Functions weekly.
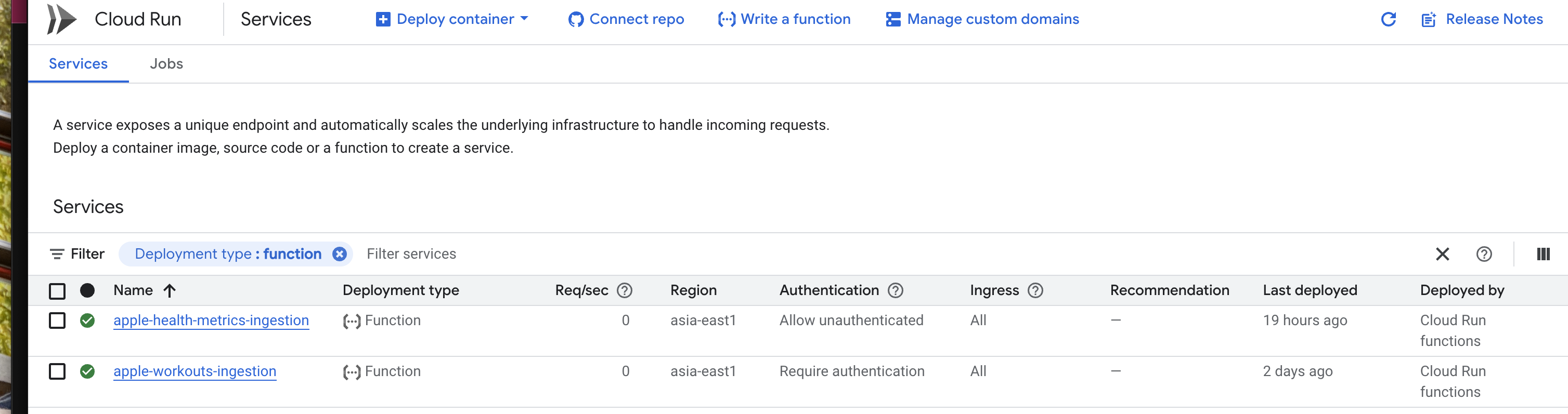
The Cloud Function:
- Authenticates using credentials stored in Secret Manager
- Fetches the latest .csv files from Google Drive
- Cleans and transforms them using pandas
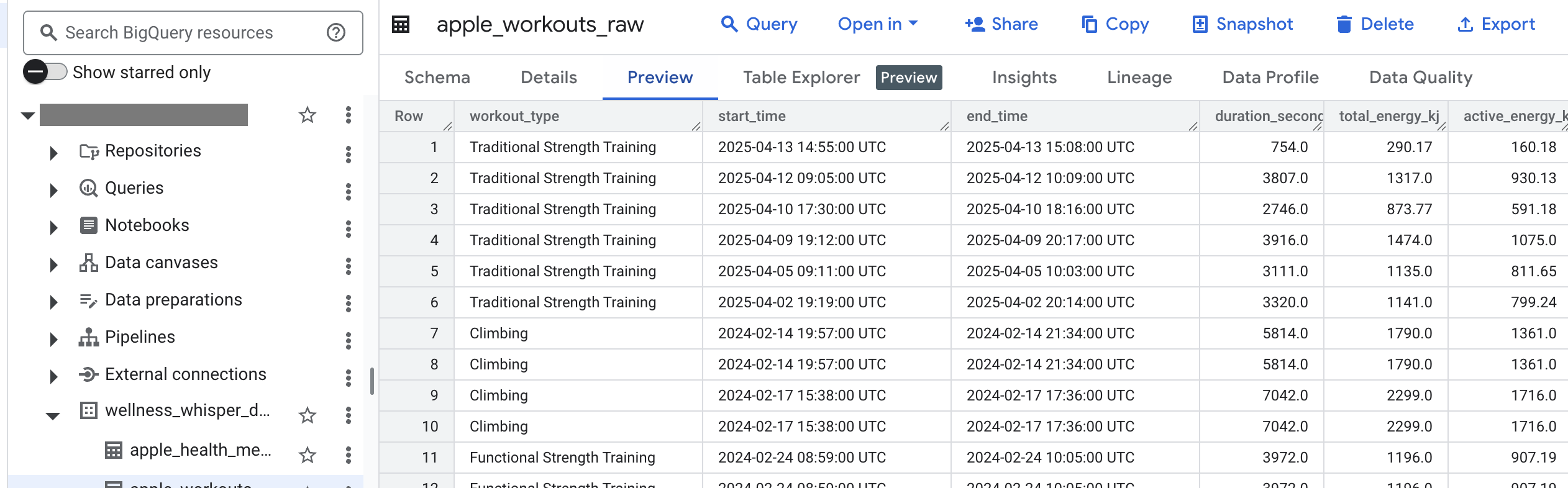
- Loads them into BigQuery tables: apple_workouts_raw and apple_health_metrics_raw
BigQuery
- Stores raw, structured data
- Enables downstream analytics (e.g. trends, forecasting, visualization)
Implementation Details
Step 1: Enable APIs and Prepare GCP Permissions
I will enable the necessary APIs and prepare for GCP permissions first:
# Enable required services
gcloud services enable cloudfunctions.googleapis.com cloudscheduler.googleapis.com \
secretmanager.googleapis.com bigquery.googleapis.com drive.googleapis.com
# Create service account
gcloud iam service-accounts create apple-health-ingestion \
- display-name="Apple Health Data Ingestion"
# Grant BigQuery permissions
gcloud projects add-iam-policy-binding YOUR_PROJECT_ID \
- member="serviceAccount:apple-health-ingestion@YOUR_PROJECT_ID.iam.gserviceaccount.com" \
- role="roles/bigquery.dataEditor"
# Create and store service account key
gcloud iam service-accounts keys create service-account-key.json \
- iam-account=apple-health-ingestion@YOUR_PROJECT_ID.iam.gserviceaccount.com
# Store key in Secret Manager
gcloud secrets create google-drive-key - data-file=service-account-key.jsonCreate the BigQuery dataset and tables:
# Create dataset
bq mk - location=asia-east1 wellness_whisper_dataYou can use following scripts to create a table with schema easily:
from google.cloud import bigquery
from google.api_core import retry
def create_health_metrics_table():
# Initialize the client
client = bigquery.Client()
# Define table schema
schema = [
# Timestamp
bigquery.SchemaField("date_time", "DATETIME", description="Timestamp of the health metric"),
# Heart Rate Metrics
bigquery.SchemaField("heart_rate_min_bpm", "FLOAT64", description="Minimum heart rate in BPM"),
bigquery.SchemaField("heart_rate_variability_ms", "FLOAT64", description="Heart rate variability in milliseconds"),
...
]
table_id = "your-project-id.wellness_whisper_data.apple_health_metrics_raw"
try:
table = client.create_table(
bigquery.Table(table_id, schema=schema),
exists_ok=True
)
print(f"Created table {table_id}")
except Exception as e:
print(f"Error creating table: {str(e)}")
if __name__ == "__main__":
create_health_metrics_table()Step 2: Google Drive Setup
- Share the data folder with your service account email (viewer or editor permission)
- Note the folder ID from the URL (https://drive.google.com/drive/folders/xxxx, xxxx is the folder ID)
Step 3: Cloud Function Implementation
The core of our pipeline is the Cloud Function. My project looks like this:
.
├── main.py # Cloud Function entry point
├── requirements.txt # Python dependencies
├── src/
│ └── ingestors/
│ ├── __init__.py
│ └── apple_health_metrics_ingestor.py
└── config/
└── health_metrics_config.yamlIn main.py, the entry point looks like this:
import functions_framework
from src.ingestors.apple_health_metrics_ingestor import AppleHealthMetricsIngestor
import logging
import yaml
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@functions_framework.http
def ingest_health_metrics(request):
"""Cloud Function to ingest Apple Health Metrics data."""
try:
with open('config/health_metrics_config.yaml', 'r') as file:
config = yaml.safe_load(file)
ingestor = AppleHealthMetricsIngestor(config)
ingestor.ingest()
return {"status": "success", "message": "Health data ingestion completed"}
except Exception as e:
error_message = f"Error in health metrics ingestion: {str(e)}"
logger.error(error_message)
return {"status": "error", "message": error_message}, 500And here's the ingestor implementation:
from ..utils.gdrive_utils import GoogleDriveClient
from ..utils.bigquery_utils import BigQueryClient
from google.cloud import bigquery
import pandas as pd
import logging
from datetime import datetime
class AppleHealthMetricsIngestor:
def __init__(self, config):
"""Initialize with configuration for GDrive and BigQuery."""
self.config = config
self.gdrive_client = GoogleDriveClient() # Handles Google Drive operations
self.bq_client = BigQueryClient() # Handles BigQuery operations
def ingest(self):
"""Main ingestion process."""
try:
files = self.gdrive_client.list_files(
folder_id=self.config['gdrive']['folder_id'],
pattern="HealthMetrics-*.csv"
)
logger.info(f"Found {len(files)} files to process")
for file in files:
df = self.gdrive_client.read_csv_from_drive(file['id'])
df = self.transform(df)
self.bq_client.insert_dataframe(df)
logger.info(f"Processed file: {file['name']}")
except Exception as e:
logger.error(f"Ingestion failed: {str(e)}")
raise
def transform(self, df):
"""Basic data transformation. -- you can implement more complex logic as you like"""
df['date_time'] = pd.to_datetime(df['Date'])
numeric_cols = ['step_count', 'heart_rate_avg_bpm', 'active_energy_kj']
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
# Add metadata
df['ingestion_date'] = pd.Timestamp.now()
return dfStep 4: Deployment
Deploy the functions using deployment scripts:
# Deploy Cloud Function
gcloud functions deploy apple-health-metrics-ingestion \
- gen2 \
- runtime=python39 \
- region=asia-east1 \
- source=. \
- entry-point=ingest_health_metrics \
- trigger-http \
- memory=512MB \
- timeout=540s \
- service-account=apple-health-ingestion@YOUR_PROJECT_ID.iam.gserviceaccount.com
# get YOUR_FUNCTION_URL
gcloud functions describe apple-health-metrics-ingestion \
--gen2 \
--region=asia-east1 \
--format='get(serviceConfig.uri)'
# Set up Cloud Scheduler
gcloud scheduler jobs create http apple-health-metrics-weekly-ingestion \
- location=asia-east1 \
- schedule="0 0 * * 0" \
- uri="YOUR_FUNCTION_URL" \
- http-method=POST \
- oidc-service-account-email=apple-health-ingestion@YOUR_PROJECT_ID.iam.gserviceaccount.comAfter all these steps, your workflow in GCP may looks like below:
BigQuery Table
Cloud Scheduler
Cloud Run Function
Takeaways
Building this pipeline was a fun blend of personal health tracking and cloud automation. A few key lessons stood out:
- Automation is everything. Manual exports are fine once or twice, but setting up daily syncs with Health Auto Export and Google Cloud means I never have to think about it again.
- GCP has all the pieces you need. From Google Drive to BigQuery, Cloud Functions, and Cloud Scheduler — everything plays well together with just a bit of setup.
Next up: I'll explore how to enrich this pipeline with Strava data, add a frontend to ask questions in plain English, and answer with a multi-agent workflow.